Использование деревьев решений в задачах прогнозной аналитики

В последние десятилетия одними из самых популярных методов решения задач прогнозной аналитики являются методы построения деревьев решений. Эти методы универсальны, используют эффективную процедуру вычислений, позволяют найти достаточно качественное решение задачи. Именно об этих методах я расскажу в данной статье.
Дерево решений
Дерево решений – структура данных, в процессе обхода которой в каждом узле в зависимости от проверяемого условия принимается определенное решение – перемещение по той или иной ветке дерева от корня к «листьевым» (конечным) вершинам. В «листьевой» вершине дерева содержится искомое значение интересующего атрибута. Деревья решений могут оценивать значения категориальных атрибутов (конечное число дискретных значений), а также количественных. В первом случае говорят о задаче классификации – отнесении объекта к одному из «классов», определяемых атрибутом (например, Да/Нет, Хорошо/Удовлетворительно/Плохо и т.д.). Во втором случае говорят о задаче регрессии, то есть об оценке количественной величины.
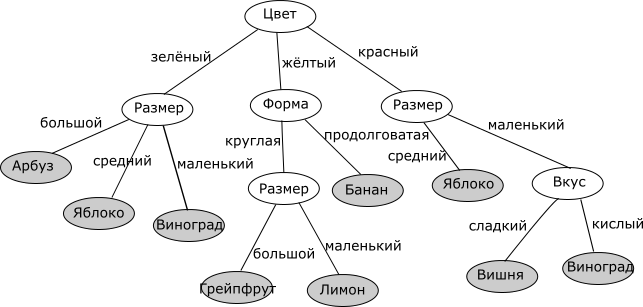
Мы рассмотрим алгоритм, позволяющий построить такое дерево решений для оценивания и предсказания значений интересующего нас категориального атрибута анализируемого набора данных на основе значений других атрибутов (задача классификации).
Вообще способов построить дерево может быть бесконечно много – атрибуты можно рассматривать в разном порядке, проверять в узлах дерева различные условия, останавливать процесс, используя разные критерии. Но нас интересуют только деревья, которые наиболее точно оценивают значение атрибута, с минимальной ошибкой, а также позволяют выявлять зависимость между атрибутами и успешно выполнять прогнозирование значений атрибутов на новых данных. К сожалению, не существует хороших алгоритмов, позволяющих гарантированно найти такое «оптимальное» дерево (за приемлемое время). Однако существуют достаточно хорошие алгоритмы, которые пытаются построить «почти оптимальное» дерево, выполняя на каждой итерации определенный «локальный» критерий оптимальности в надежде, что получившееся дерево тоже в целом будет «оптимальным». Такие алгоритмы называются «жадными». Именно такой алгоритм мы и рассмотрим.
Алгоритм построения дерева решений
Принцип построения дерева следующий. Дерево строится «сверху вниз» от корня. Начинается процесс с определения, какой атрибут следует выбрать для проверки в корне дерева. Для этого каждый атрибут исследуется на предмет, как хорошо он в одиночку классифицирует набор данных (разделяет на классы по целевому атрибуту). Когда атрибут выбран, для каждого его значения создается ветка дерева, набор данных разделяется в соответствии со значением к каждой ветке, процесс повторяется рекурсивно для каждой ветки. Также следует проверять критерий остановки.
Главный вопрос – как выбирать атрибуты. В соответствии с идеей подхода, когда в концевых узлах дерева (листьях) будет искомый нами класс целевого атрибута, необходимо, чтобы при разбиении набора данных в каждом узле получавшиеся наборы данных были все более однородны в плане значений классов (например, большинство объектов в наборе принадлежало бы к классу Арбуз). И необходимо определить количественный критерий, чтобы оценить однородность разбиения.
Энтропия
Рассмотрим набор вероятностей pi, описывающий вероятность соответствия строки данных в нашем наборе (обозначим его X) классу i. Вычислим следующую величину:
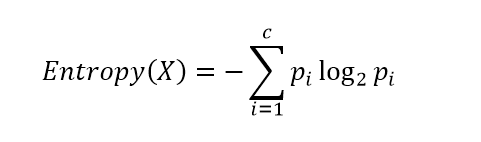
Данная функция представляет собой так называемую энтропию. Энтропия возникла в теории информации и описывает количество информации (в битах), которое необходимо, чтобы закодировать сообщение о принадлежности случайно выбранного объекта (строки) из нашего набора X к одному из классов и передать его получателю. Если класс только один, получателю ничего не нужно передавать, энтропия равна 0 (принимается, что 0log20 = 0). Если все классы равновероятны, то потребуется log2c бит (c – общее количество классов) – максимум функции энтропии.
Далее, для выбора атрибута, для каждого атрибута A вычисляется так называемый прирост информации:
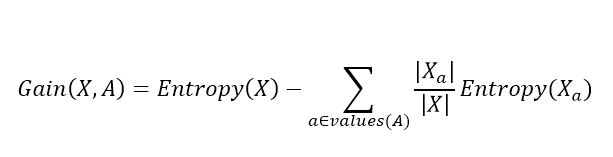
Где values(A) – все принимаемые значения атрибута A, Xa – подмножество набора данных, где A = a, |X| – количество элементов во множестве. Данная величина описывает ожидаемое уменьшение энтропии после разбиения набора данных по выбранному атрибуту. Второе слагаемое – это сумма энтропий для каждого подмножества, взятая со своим весом. Общая разница описывает, как уменьшится энтропия, сколько мы сэкономим бит для кодирования класса случайного объекта из набора X, если мы знаем значения атрибута A и разобьем набор данных на подмножества по данному атрибуту.
Алгоритм выбирает атрибут, соответствующий максимальному значению прироста информации.
Когда атрибут выбран, исходный набор разбивается на подмножества в соответствии с его значениями, исходный атрибут исключается из анализа, процесс повторяется рекурсивно.
Процесс останавливается, когда созданные подмножества стали достаточно однородны (преобладает один класс), а именно когда max(Gain(X,A)) становится меньше некоторого заданного параметра Θ (величина, близкая к 0). Как альтернативный вариант, можно контролировать само множество X, и когда оно стало достаточно мало или стало полностью однородным (только один класс), останавливать процесс.
Жадный алгоритм построения дерева решений
Более структурно алгоритм можно представить следующим образом:
1. Если max(Gain(X,A)) < Θ, создать лист с меткой преобладающего класса.
2. Если не осталось атрибутов для разбиения, создать лист с меткой преобладающего класса.
3. Иначе:
A. выбрать атрибут, соответствующий максимуму Gain(X,A);
B. создать ветку для каждого значения атрибута;
C. для каждой ветки:
I. построить подмножество Xa, исключив при этом атрибут A из множества атрибутов;
II. рекурсивно вызвать алгоритм для подмножества Xa.
Если атрибут количественный (например, вещественное число), то разбиение по нему выполняется в форме теста A ≤ a0 и формируются две ветки (истина и ложь). Существует способ оптимального подбора a0 также с использованием идеи прироста информации.
Если же целевой атрибут количественный, то решается задача не классификации, а регрессии (оценки количественного значения атрибута по значениям других атрибутов). В этом случае используется не максимизация прироста информации, а минимизация суммы квадратов отклонений.
Как это работает
Рассмотренный алгоритм был предложен его автором Джоном Квинланом (Quinlan) и известен как алгоритм ID3 (Iterative Dichotomiser версии 3).
Давайте на небольшом примере рассмотрим, как ID3 выбирает атрибуты, так как это ключевой момент. Пример совершенно неполиткорректный, но, тем не менее, удобен для иллюстрации и использовался и самим Квинланом.
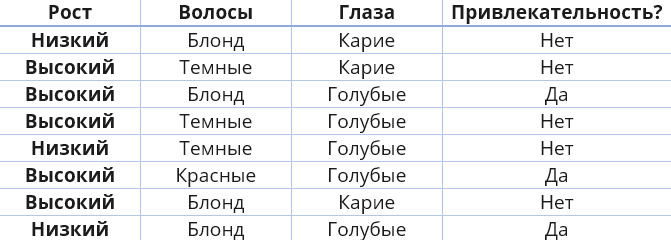
Нашим целевым атрибутом для дерева решений будет атрибут «Привлекательность?». Еще раз отмечу, что пример неполиткорректный и не имеет никакого отношения к реальности :))
Вычислим энтропию с учетом, что у нас простая бинарная классификация Да/Нет по целевому атрибуту.
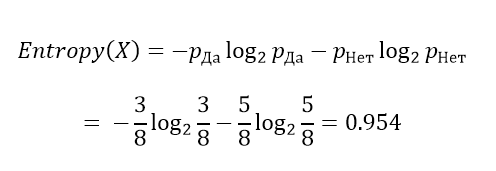
Теперь для каждого атрибута оценим прирост информации:

Таким образом, наибольший прирост информации на первом шаге обеспечивает атрибут «Волосы». Именно он является самым информативным и наилучшим образом разделяет набор данных на наши классы Да/Нет. И это видно невооруженным глазом, если посмотреть в исходную таблицу данных: («Волосы»=Темные) сразу влечет («Привлекательность?»=Нет), («Волосы»=Красные) сразу влечет («Привлекательность?»=Да). Про Блонд ничего сказать нельзя.
Атрибут «Рост», наоборот, самый неинформативный и значения практически не имеет.
Полностью достроить дерево предлагаю вам самостоятельно.
Алгоритм ID3 реализован в Prognoz Platform в модуле интеллектуального анализа данных. Он позволяет построить дерево решений и визуализировать его в виде правил «Если..,то», а также использовать дерево для классификации путем заполнения пустых значений целевого атрибута. Функции интеллектуального анализа можно вызвать из любого инструмента применительно к текущей таблице с данными, а также использовать таблицу БД.
Преимущества и недостатки деревьев решений
Деревья решений обладают определенными особенностями. Начнем с преимуществ:
- простота интерпретации и наглядность;
- возможность работы как с категориями, так и с количественными значениями;
- универсальность в плане решения задач и классификации, и регрессии;
- возможность работы с пропусками в данных (пустыми значениями атрибутов). Причем деревья решений можно использовать для заполнения пропусков наиболее вероятным значением;
- хорошая производительность в процессе классификации по уже построенному дереву (так как алгоритм поиска в дереве весьма эффективен даже для больших наборов данных).
Не обошлось и без недостатков. Среди них:
- нестабильность процесса. Нередко небольшие изменения в наборе данных могут приводить к построению совершенно другого дерева. Это связано с иерархичностью дерева. Изменения в узле на верхнем уровне ведут к изменениям во всем дереве ниже.
- сложность контроля размера дерева. Размер дерева является критическим фактором, определяющим качество решения задачи. При использовании простых критериев остановки деревья часто растут или очень короткими, или очень большими.
- неадекватность разделения на классы в сложных случаях. В простейших деревьях решений разбиение в узлах происходит по значению одного атрибута, параллельно, так сказать, осям координат. В данном случае каждый атрибут – это ось координат со своими значениями. И дерево «нарезает» все пространство на «параллелепипеды», внутри которых и группируются точки набора данных, соответствующие тому или иному классу. Иногда такое разделение не может точно описать сложные области, образуемые точками, принадлежащими определенному классу.
- критерий прироста информации характеризуется склонностью предпочитать атрибуты, имеющие большое число различных значений. В предельном случае у каждой строки может быть свое значение атрибута. Тогда второе слагаемое в будет равно 0, и прирост будет максимальным.
Более продвинутые алгоритмы построения деревьев позволяют решать указанные проблемы.
Заключение
Деревья решений – вполне типичный пример алгоритма так называемого индуктивного обучения «по прецедентам», когда на основе значений атрибутов исходных данных строится некоторая решающая функция, оцениваются параметры модели и т.п. То есть в этом случае прогнозную модель конструирует не пользователь, а алгоритм – автоматически на основе исходных данных. Пользователь же, выбирая метод (в нашем случае деревья решений), определяет некий класс моделей, которые могут быть построены и обучены с помощью данного алгоритма.
В следующей статье я расскажу о некоторых модификациях процесса построения деревьев, позволяющих повысить их качество, в том числе суперпопулярный в последние годы метод Random Forest, использующий подход ансамблевого моделирования.